Why ReactiveX operators are hard to make and InteractiveX operators aren't
Full-featured reactive stream libraries, like Rx, come with a very large set of operators to create, transform, combine and otherwise process the corresponding streams. Creating your own operators with support for back-pressure is notoriously difficult.
Coroutines and channels are designed to provide an opposite experience. There are no built-in operators, but processing streams of elements is extremely simple and back-pressure is supported automatically without you having to explicitly think about it.
from Kotlin's guide to reactive channels
In principle, it's just an inversion of control between a callback-based in ReactiveX and await/suspend approach in InteractiveX. But practically, it's a whole lot more than inversion of control. The kicker is how much work the library can throw to the scheduler. In InteractiveX, it's a lot; in ReactiveX, it's not.
As a ReactiveX Observable, you're looking out to your crowd of subscribers holding a new value to hand out. Who do you give it to? This shouldn't actually be the Observable's choice, because the distribution policy is totally application-specific. Since you're responsible for the distribution, the application gives you its preferred policy in the form of some configuration, sometimes in the form of a choice of library-defined scheduler like ReactiveX does. Now what do you do?
An obvious option is to set up our own scheduler[s]. They need to span the cases that users want which is quite a few. However, the point is actually that this list isn't crazy — a lot of built-in schedulers in many "Reactive" languages are powerful enough to already have these baked in to juggle threads. Let's throw the work to the built-in scheduler then.
Cool, so we've tossed the scheduler a list of our subscribers, stashed our new value somewhere publicly-accessible that the subscribers can pull once they wake up, and yielded to the scheduler until next value. When a subscriber wants to quit, that's fine; we'll just forward this to the scheduler as well to pop that subscriber from its waiting list. With the scheduler doing all the hard work, we take a half-day.
Buffer our values, yield control, built-in scheduler wakes sleeping subscribers... aaand we've implemented InteractiveX.
If we look at flow diagrams of the control passing around the application, we can see how the deep stack of ReactiveX (Observable calling subscribers) turns flat in InteractiveX (built-in scheduler calling subscribers). Straight from the definition, here's the basic structure of any reactive code, with streams sitting between the event sources and the application:
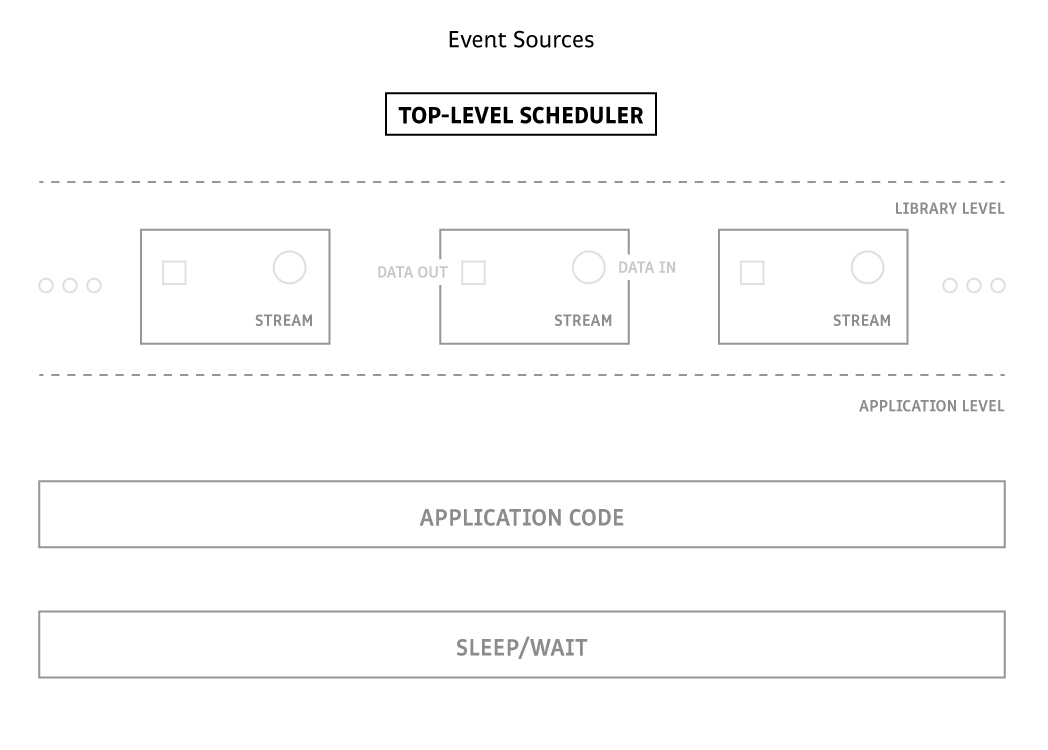
The choice between reactive and interactive is what fills in the arrows between these blocks. We'll distinguish the flow of control — which deepens the stack or results from a context switch — to data gets and sets (e.g. writing to buffer) which don't.

As promised, ReactiveX is deep because the control flows mostly one way from the scheduler down to the application.
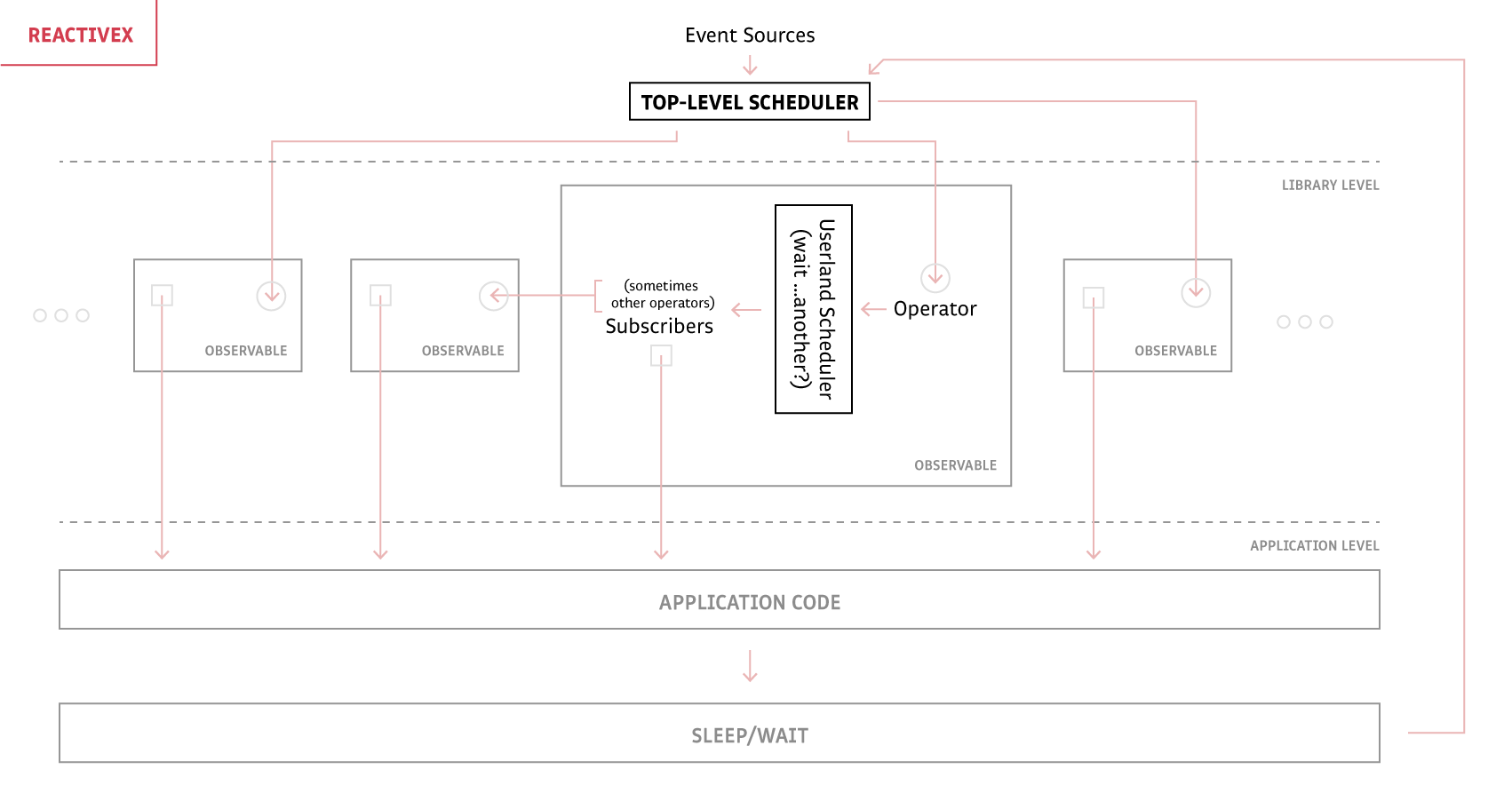
The InteractiveX flow is far more complicated because of all the return flow to the scheduler, but it's important to keep in mind the complexity lies all with the scheduler. To the user code, a return flow is absolutely undramatic: just an await or yield.
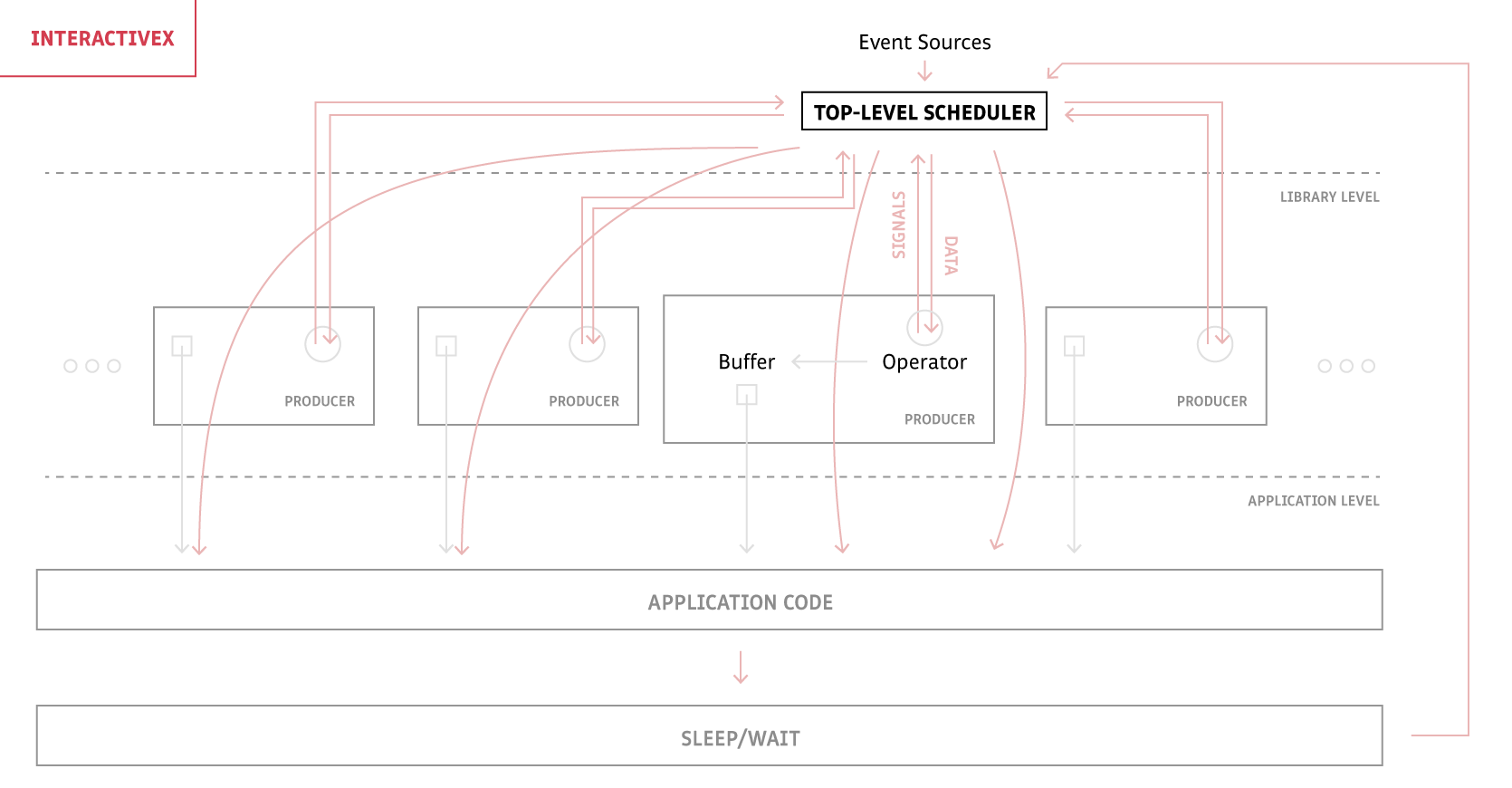
Note the separation between the application and the library (that I mentioned in this aside) as the control transfer turns into a data transfer! Bam, we've just separated concerns:
- Publishers concern themselves with publishing,
- Consumers concern themselves with consuming,
- The scheduler concerns itself with scheduling.
- How to make a ReactiveX